CSAPP cache lab
cache _lab
PART A
要求
使用 c 语言模拟 cpu 的 cache 的组织方式,以及行为, 运行 csim 时候指定cache 的 set数 行数 和blcok 数,根据文件里的读写指令来模拟 cahce 的 hit miss 和 eviction
流程
修改 csim.c 文件
编译 gcc csim.c cachelab.c -o csim
测试运行 ./csim -s 4 -E 2 -b 4 -t traces/yi.trace
得分 make && ./test-csim
基本知识
我们要获取 虚拟地址 的数据,首先应该从 Cache 中获取,取不到再去 内存的虚拟地址获取。
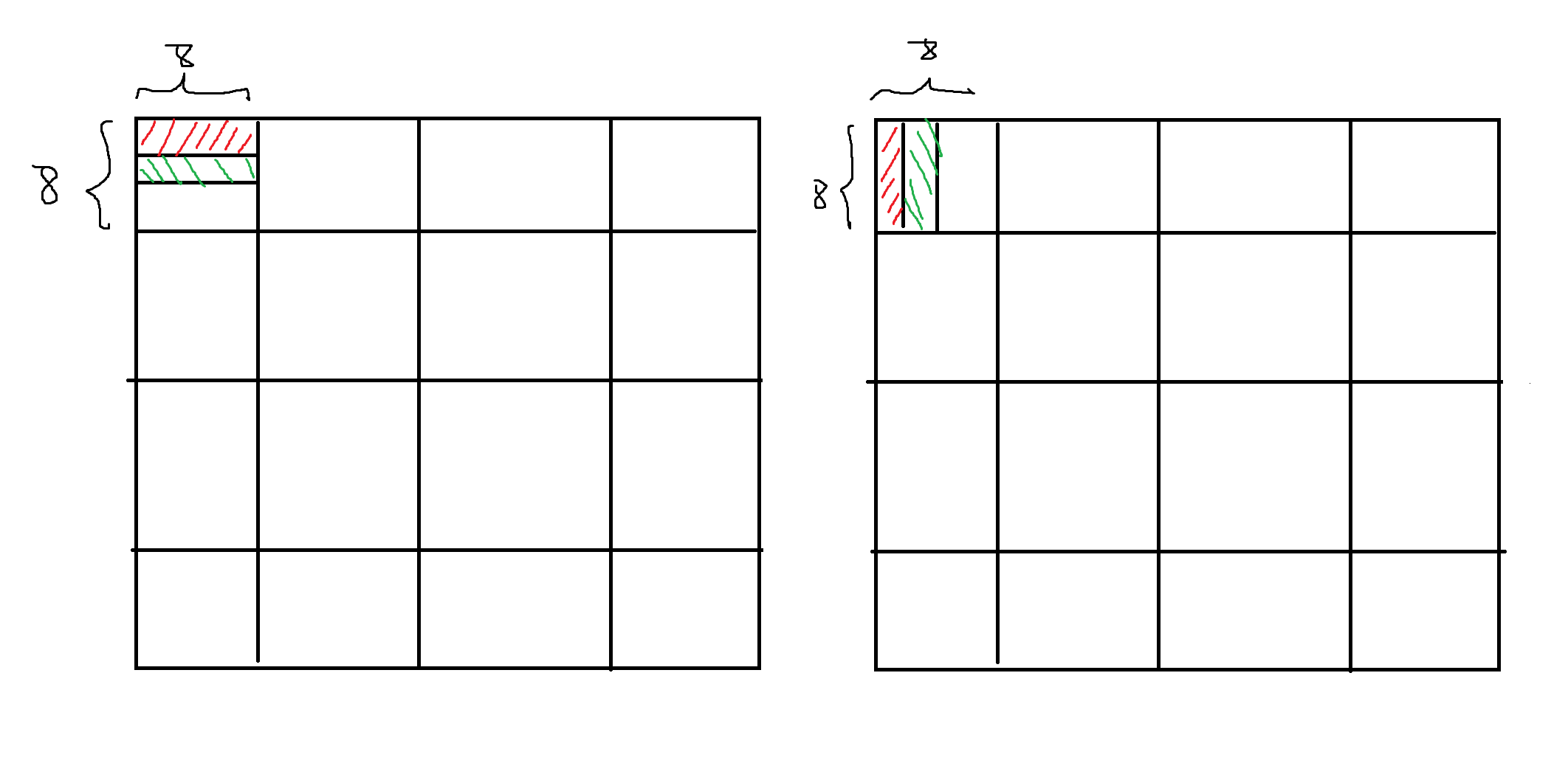
CPU Cache 组成如下,一个Cache 包含 S 个Set ,一个 Set 包含 E 个 Line,一个Line 包含 b 个 block,
我们想要的结果就在 block 中
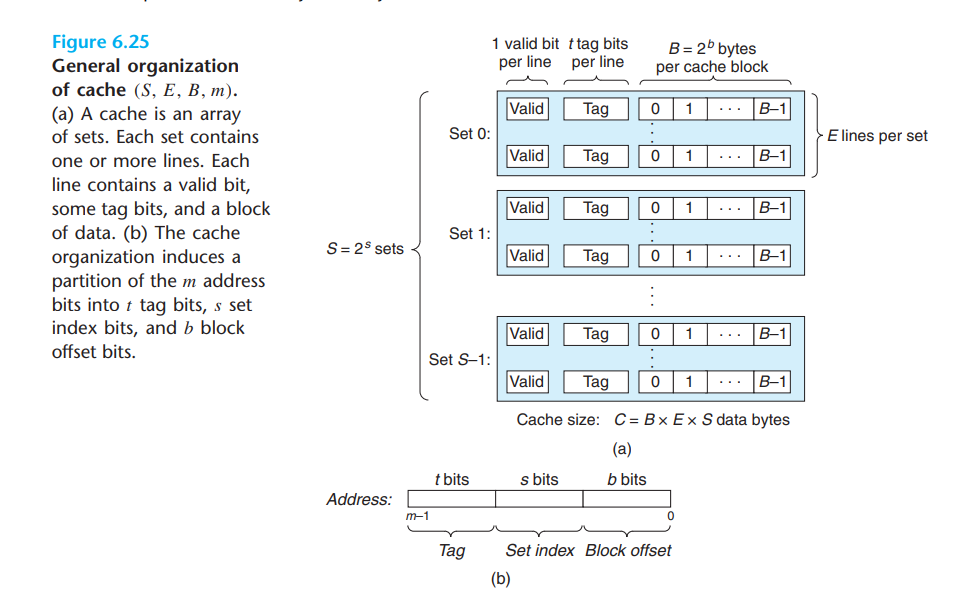
要根据 虚拟地址 找到 block,先把虚拟地址分成 3 部分
系统规定好
-
Cache 有 S 个 Set,S = 2^s,因此下图 Set Index 就有 s 位
-
每个 Set 的 每一个 Line 有 B 个 Block,B = 2 ^ b,因此 Block offset 有 b位
-
剩下的就表示 Tag
开始查找
根据中间 s 位,定位到到第 Set 的 Index
然后指定 Index的 Set 中 一行行寻找 Tag 是否相同的,找到 Line
根据最后 b 位,定位到到第 Cache Block 的 Index,找到具体第 Index 个 Block
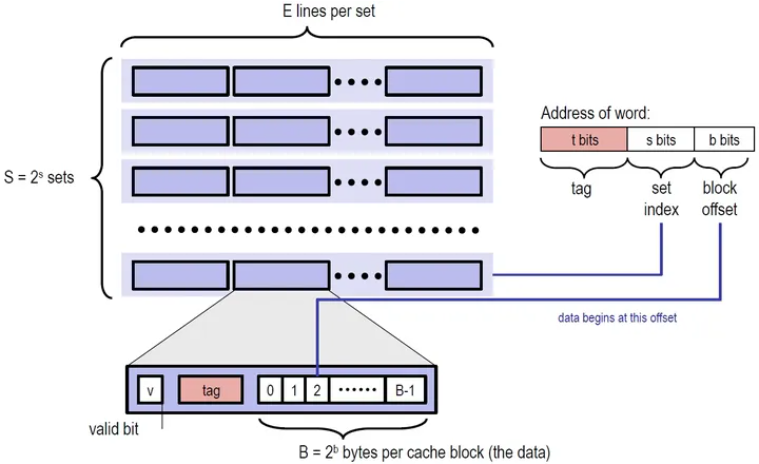
举例
当规定s = 4 E = 2 b = 4
有16个Set,每个 Set 2 个 Line,每个 Line 有 16个 Block
指令 L 210,1 ,load 0X210地址的数据,大小为1
0X210 = 000.0001000010000(64位二进制)
block offset (4位)= 0000 = >第 0个 Block
set index (4位) = 0001 =>第 1 个 Set
tag (剩下位)= 00…..0010 => Set 中 编号为 2 的 Tag
实践
替换策略 LRU
为每个Set 指定一个 LRU队列,当 Set 缓存满了需要 eviction,根据LRU队列来指定替换哪个
typedef struct {
int size;//当前缓存大小
int capacity;//缓存容量
Hash* table;//哈希表
LinkList head;// 指向最近使用的数据
LinkList tail;// 指向最久未使用的数据
} LRUCache;
typedef struct {
int flag;
int tag;
int block;
} CACHE_SET_LINE;
typedef struct {
int flag;
CACHE_SET_LINE *myLine[512];
int linNum;
LRUCache *lruCache;
} CACHE_SET;
typedef struct {
CACHE_SET *mySet[512]; // 数组中每个元素是一个 set 结构体
int setNum;
} CACHE;
寻找Cache
void handelS(CACHE *cachePtr, char *from, char *to, int s, int e, int b) {
char *endptr;
long fromInt = strtol(from, &endptr, 16);
printBinary(fromInt);
//1. 把地址解析成 setIndex tag blockIndex
int blockIndex = (fromInt) & ((1 << b) - 1);
int setIndex = (fromInt >> b) & ((1 << s) - 1);
int tag = (fromInt >> (b + s)) & ((1 << (64 - b - s)) - 1);
printf("tag:%d setIndex:%d blockindex:%d \n", tag, setIndex, blockIndex);
//2. 找到Set
CACHE_SET *setPtr = cachePtr->mySet[setIndex];
LRUCache *lruPtr = setPtr->lruCache;
int linNum = setPtr->linNum;
int fullNum = 0;
int emptyNum = 0;
int hitFlag = 0;
//3. 找到 Line,判断是 hit miss eviction
for (int i = 0; i < linNum; ++i) {
//逐行遍历
CACHE_SET_LINE *lineStr = setPtr->myLine[i];
//tag 相等 HIT
if (lineStr->tag == tag) {
hitFlag = 1;
hitsTime++;
lRUCacheGet(lruPtr, tag);
break;
} else if (lineStr->tag == -1) {
emptyNum++;
} else {
fullNum++;
}
}
//MISS 有空位不用替换
if (emptyNum > 0 && hitFlag == 0) {
for (int i = 0; i < linNum; ++i) {
CACHE_SET_LINE *lineStr = setPtr->myLine[i];
if (lineStr->tag == -1) {
lineStr->tag = tag;
lineStr->block = b;
int deleteKey = 1;
lRUCachePut(lruPtr, tag, b,&deleteKey);
break;
}
}
missesTime++;
}
// Miss 需要替换 EVICTION
if (fullNum == e) {
missesTime++;
evictionsTime++;
//lru淘汰
int deleteKey = -1;
lRUCachePut(lruPtr, tag, b, &deleteKey);
//替换
for (int i = 0; i < setPtr->linNum; ++i){
//逐行遍历替换
CACHE_SET_LINE *lineStr = setPtr->myLine[i];
if (lineStr->tag == deleteKey) {
lineStr->tag = tag;
break;
}
}
}
}
PART B
./csim-ref -v -s 5 -E 1 -b 5
32个组,每组一行,每个行32byte
采用最简单的转置
void trans(int M, int N, int A[N][M], int B[M][N])
{
int i, j, tmp;
for (i = 0; i < N; i++)
{
for (j = 0; j < M; j++)
{
tmp = A[i][j];
B[j][i] = tmp;
}
}
}
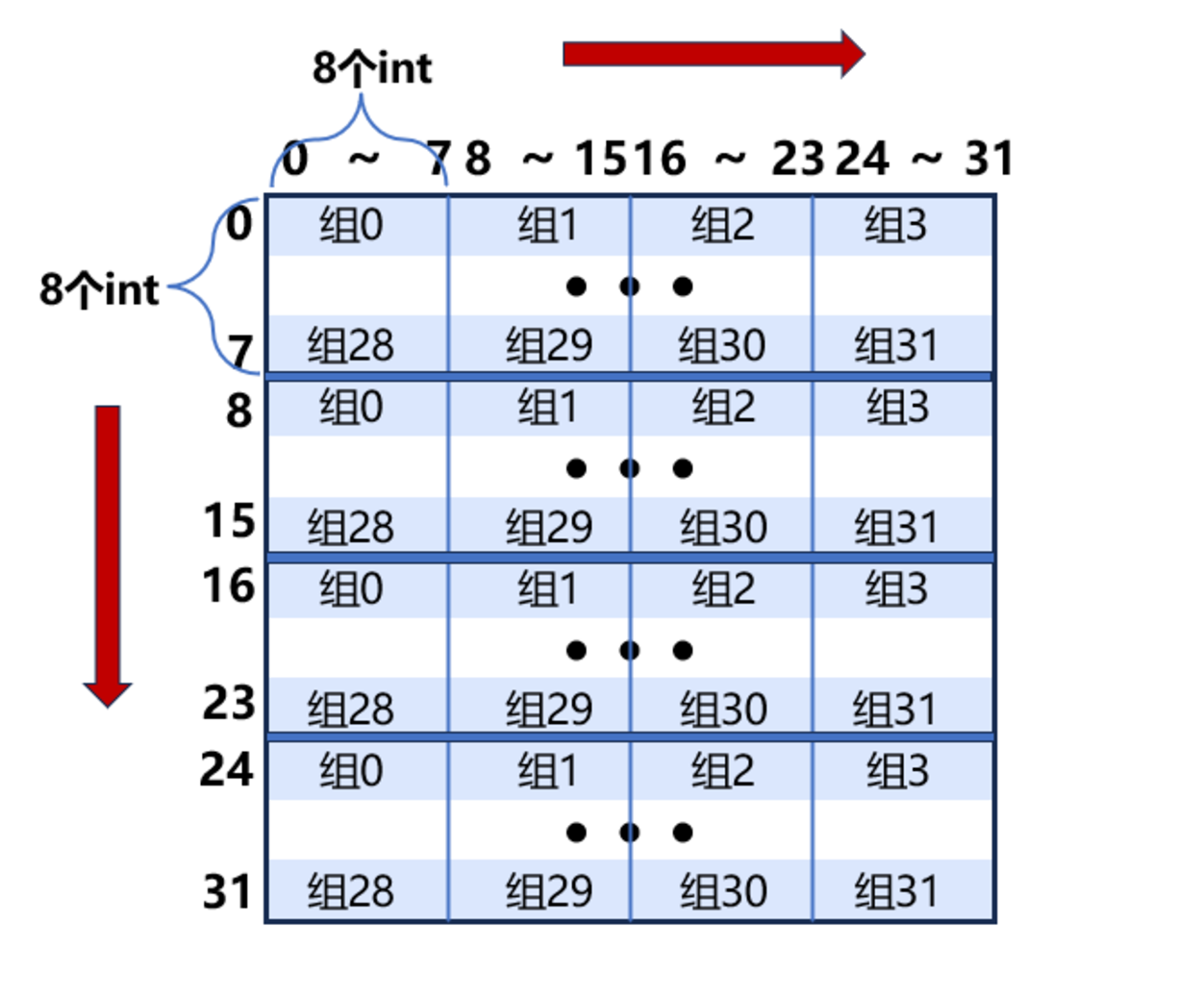
数组A、B每部分映射的缓存组如下图所示
分析缺陷
程序依次访问的顺序为
A[0][0] B[0][0],A[0][1] B[1][0], A[0][2] B[2][0],A[0][3] B[3][0]...A[0][7]B[7][0]
访问A[0][0] miss,set:0,tag:0,保存A[0][0]到A[0][7]的缓存块
访问B[0][0] miss,set:0,tag:0,驱逐A[0][0]到A[0][7]的缓存块,保存B[0][0]到B[0][7]的缓存块
访问A[0][1] miss,set:0,tag:0,驱逐B[0][0]到B[0][7]的缓存块,保存A[0][0]到A[0][7]的缓存块
访问B[1][0] miss,set:4,tag:0,保存B[1][0]到B[1][7]的缓存块
访问A[0][2] miss,set:0,tag:0,HIT
访问B[2][0] miss,set:5,tag:0,保存B[2][0]到B[2][7]的缓存块
访问A[0][3] miss,set:0,tag:0,HIT
访问B[3][0] miss,set:6,tag:0,保存B[3][0]到B[3][7]的缓存块
....
可以总结出,
1. 对角线的情况A[i][i]和B[i][i],tag和set都是一样,B总是会驱逐A的缓存,(无法避免)
2. A是一行一行访问,先访问第一个,后面的7个数字都将纳入缓存
3. B是一列一列访问,总是会出现miss
综上所述
A出现miss的次数 [(32 * 32)/8=128次]每8个数子的第一个会miss,31(32个对角线,A[0][0]已经miss过一次了)=128+31=159
A出现miss的次数=32*32=1024(总是会miss或者驱逐)
159+1024=1183
常规移动,影响的行
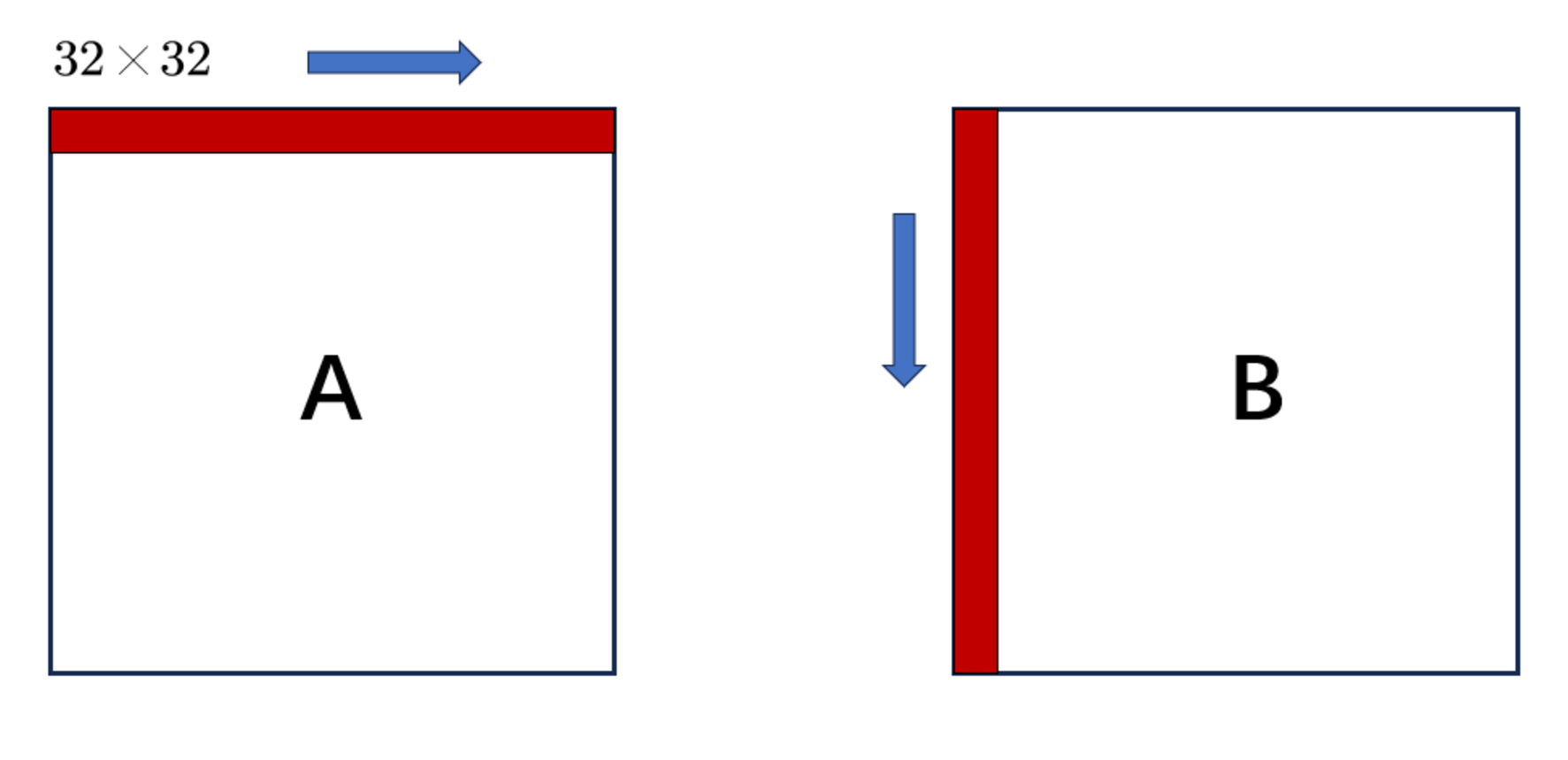
32x32
1-1优化
我们发现矩阵B对缓存的利用率很低,总是miss,
因为B是一列一列访问,B[0][0]miss,B[0][0]-B[0][7]刚刚换入缓存,等到了访问B[4][0],又与B[0][0],冲突了,直接驱逐,造成B[0][0]-B[0][7]还未使用就又替换新的。
为了解决这个问题,使用分块,限制B只先访问一列32个,再来访问第二列,例如吧分成8X8的一块,即使B先访问列,也是先一列B[0][0]-B[3][0],在访问后面的列,缓存都用上了,再访问B[4][0]-B[7][0],驱逐之前的缓存,这样不会发生刚加入缓存还未使用后续的块就产生驱逐。
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
// 使用分块8×8的方法来进行转置
for(int i=0; i<M; i+=8)
{
for(int j=0; j<N; j+=8)
{
for(int s=0; s<8; ++s)
{
for(int k=0; k<8; ++k)
{
B[j+k][i+s] = A[i+s][j+k];
}
}
}
}
}
1-2缺陷
遍历A[0][0]-A[0][7],B[0][0]-B[7][0],第一行第一列转置完毕之后
第二行A[1][0]的时候 会把B[1][0]的缓存驱逐,所以交叉访问会经常驱逐缓存
因此我可以先把A[0][0]-A[0][7]访问完毕,再来访问B[0][0]-B[7][0],
缓存一个8X8的块miss次数8+8(第一次访问)+(对角线),所以32x32的miss为(8+8)x16+31(对角31次)=287
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
//由于对角线部分的冲突不命中增多,导致miss的数量较大,使用的方法是将A中的一组元素(8个)使用局部变量存储在程序寄存器中,避免了A和B的加载和写回的冲突不命中
int a0, a1, a2, a3, a4, a5, a6, a7;
for(int i=0; i<N; i+=8)
{
for(int j=0; j<M; j+=8)
{
for(int k=0; k<8; ++k)
{
a0 = A[i+k][j+0];
a1 = A[i+k][j+1];
a2 = A[i+k][j+2];
a3 = A[i+k][j+3];
a4 = A[i+k][j+4];
a5 = A[i+k][j+5];
a6 = A[i+k][j+6];
a7 = A[i+k][j+7];
B[j+0][i+k] = a0;
B[j+1][i+k] = a1;
B[j+2][i+k] = a2;
B[j+3][i+k] = a3;
B[j+4][i+k] = a4;
B[j+5][i+k] = a5;
B[j+6][i+k] = a6;
B[j+7][i+k] = a7;
}
}
}
}
64x64
原来32x32时,一行可以存放4个组(一个组32byte,8个int),需要8行可以全部存满一个cache,所以分成8x8的块可以满足。
但是64x64,一行可以存放 8 个组,只需要 4 行可以全部存满一个cache,因此分成8x8,后4行又会驱逐前4行,因此分成4*4的来转置
结果
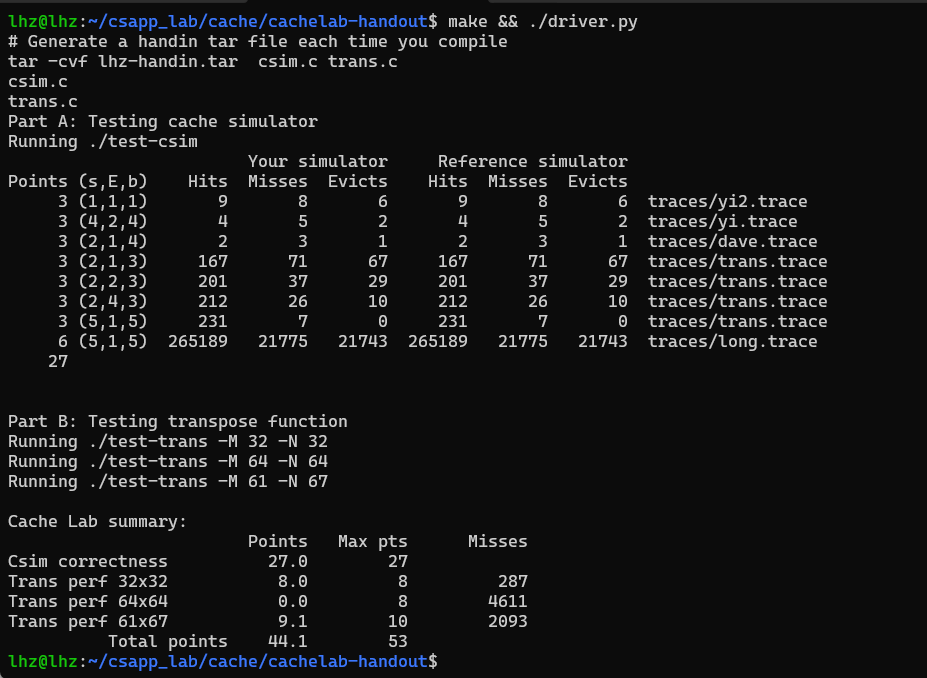
代码地址