CSAPP malloc lab
csapp malloc lab
思路:
-
把内存看作一个数组,数组的index就是内存地址,例如地址从(0x7ffff69a4010-0x7ffff7da4010),每个地址可以保存1BYTE(8位)的数据,学过java的可以理解为 byte[] arry=new byte[size]。
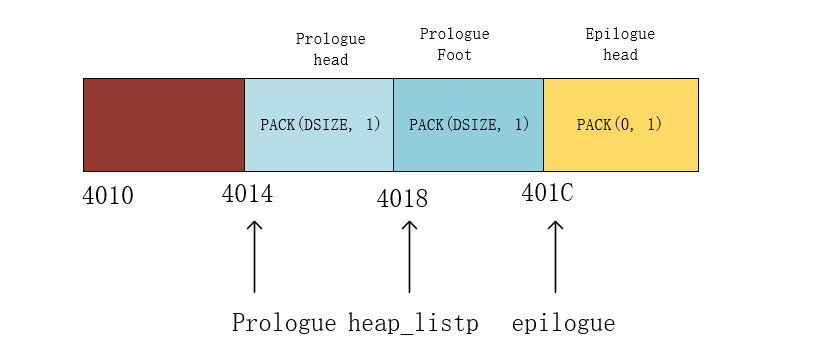
- 以word为最小单位(下图的一个矩形4byte),一个 Block 节点包含head(4byte),body(按用户分配),foot(4byte),至少 8byte 以上。
- head和foot保存 Block 的
size(头+尾+body总和)和alloc(是否空闲)。 - 初始一个word无用块,2个word头块,1个word 尾块,要扩容就在prologue和epilogue之间,移动epilogue往后即可。
- 下面例子中相同颜色(浅蓝色深蓝色区分是foot还是head)的就是一个 Block
- 每一个Block 的head大小固定,foot大小固定,body大小记录在head或foot中,因此我们就能通过对当前 block 地址的加减找到下一块或上一块的位置,以此来实现遍历。
#include "mm.h"
#include "memlib.h"
#include <stdio.h>
int main()
{
mem_init();//开辟20MB空间 0x7ffff69a4010-0x7ffff7da4010
int mmres = mm_init();
if (mmres==0)
{
int *p = (int *)mm_malloc(sizeof(int));
*p=100;
printf("hello world p= %d\n",*p);
mm_free(p);
}
}
void mem_init(void)
{
mem_heap = (char *)Malloc(MAX_HEAP);//(20*(1<<20)) /* 20 MB */
mem_brk = (char *)mem_heap;
mem_max_addr = (char *)(mem_heap + MAX_HEAP);
}
宏
//构造一个4个字节的头的内容,size代表 Block 大小, alloc 代表是否被分配(0未分配,1空闲)
//一个 Block 最小是8byte(head+foot),所以他的大小一定大于等于8(十进制)=1000(二进制),
//而且按照8byte对齐,所以后面3位一定用不上,就可以用作表示是否分配 alloc
//例如一个16byte的block,并且已分配
//10000|001 =00..010001(二进制) = 00 00 00 11(完整的头,十六进制表示 4byte)
//下面有示例
#define PACK(size, alloc) ((size) | (alloc))
/* 对该地址的Block进行读和写 */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
/* 获取地址的size和alloc */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
/*找到当前块的head指针和foot指针 */
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* 找到当前块的下一块 */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
/* 找到当前块的前一块 */
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
//代表一个word为4字节
WSIZE=4
//代表双字(Double word)8BYTE
DSIZE=8
mm_init()函数
- 初始化3个特殊的节点,包括一个起始节点,一个头节点,一个尾节点
- 再扩容4096byte的空闲的区域
int mm_init(void)
{
/* Create the initial empty heap */
if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1) //line:vm:mm:begininit
return -1;
//起始节点,4byte,无意义
PUT(heap_listp, 0); /* Alignment padding */
//头节点总共8byte,head(4)+foot(4) 无body
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); // head保存 size=8,alloc=1
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); // foot保存 size=8,alloc=1
//尾节点4byte
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); /* Epilogue header */
heap_listp += (2*WSIZE); //line:vm:mm:endinit
/* $end mminit */
/* $begin mminit */
/* Extend the empty heap with a free block of CHUNKSIZE bytes */
if (extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE; //line:vm:mm:beginextend
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL; //line:vm:mm:endextend
/* Initialize free block header/footer and the epilogue header */
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* New epilogue header */
/* Coalesce if the previous block was free */
return coalesce(bp); //line:vm:mm:returnblock
}
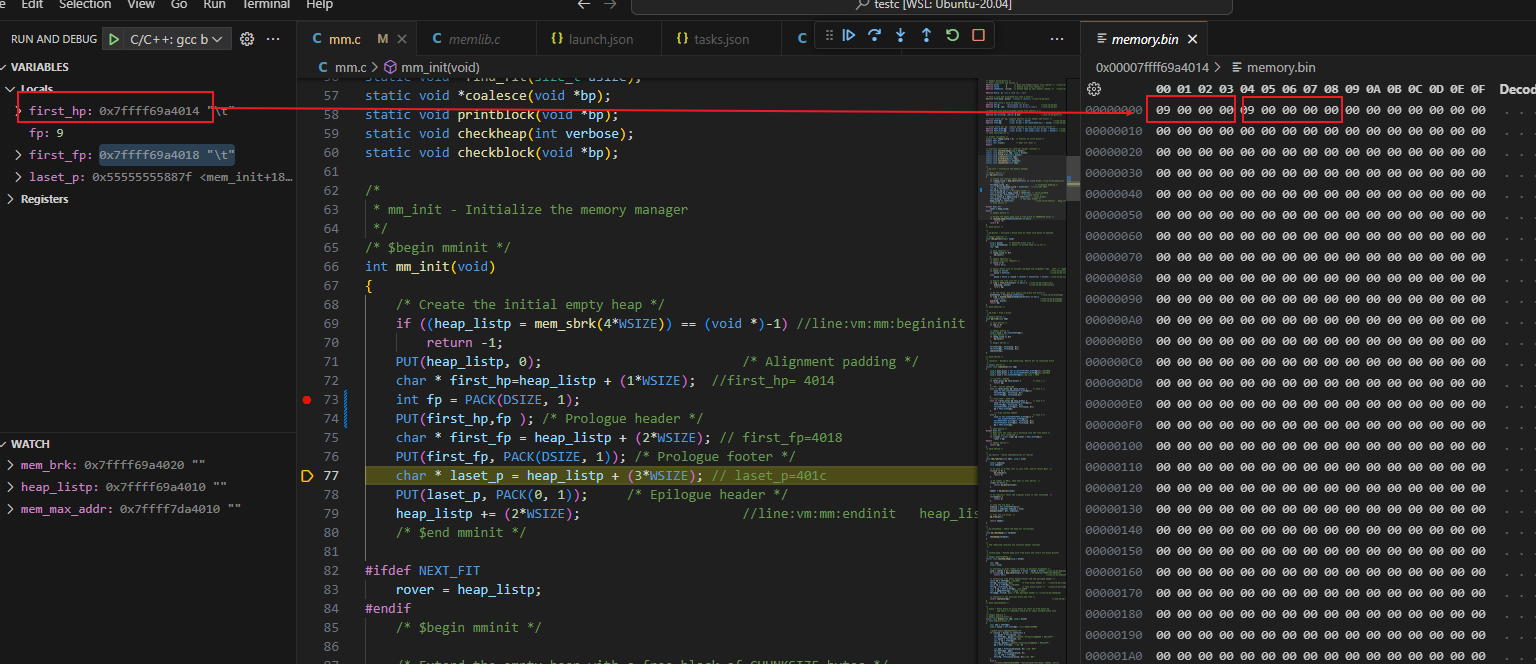
初始heap_listp = mem_sbrk(4*WSIZE)
注意图中4010代表0x7ffff69a4010,省略掉前面0x7ffff69a
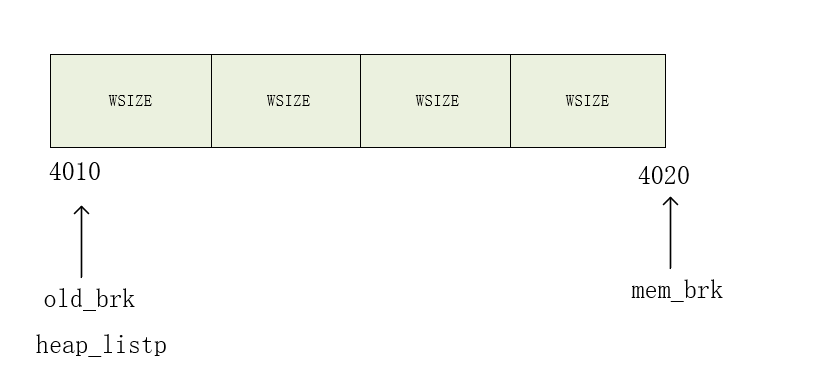
头节点和尾节点的指针
构造头节点,还没初始化头节点head和foot之前
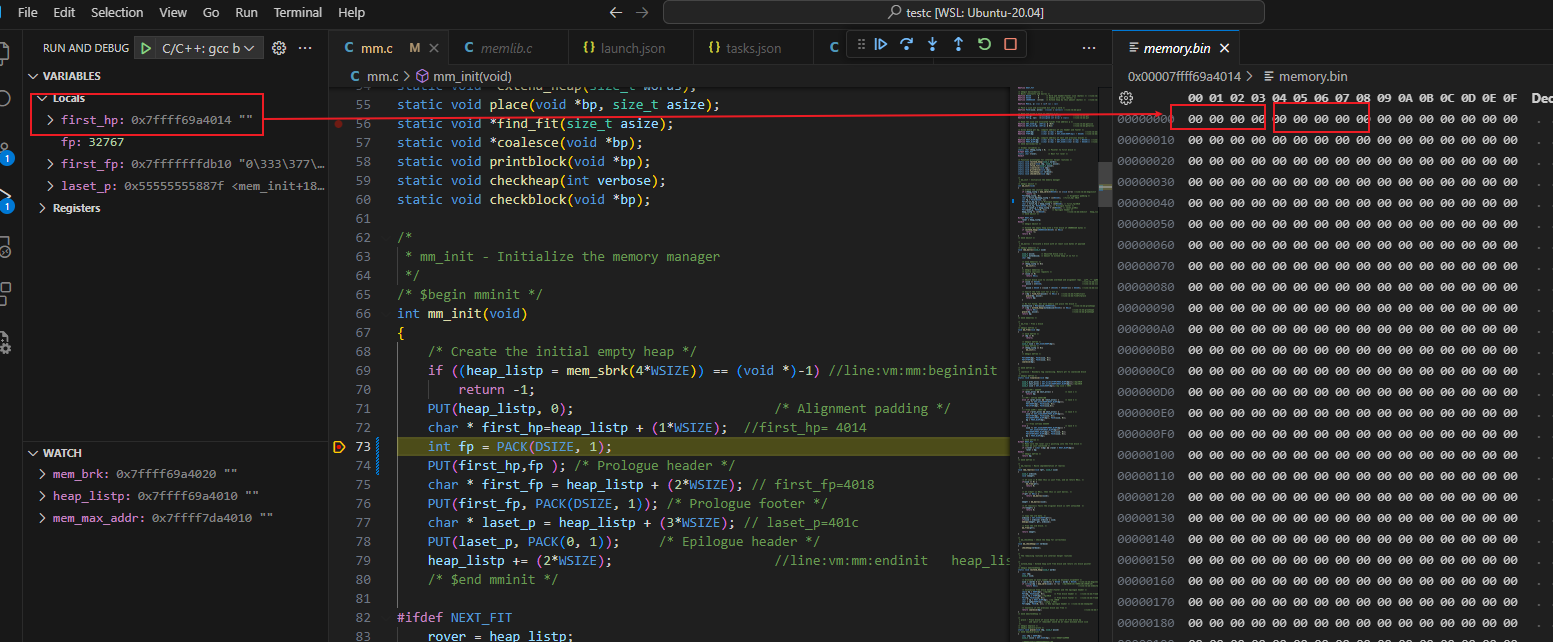
初始头节点之后,pack(8,1)=1000|001 =00..001001(二进制) = 00 00 00 09(32位的十六进制)
由于 linux 采用的是小端存储,低位放在地址的低位所以09在前面
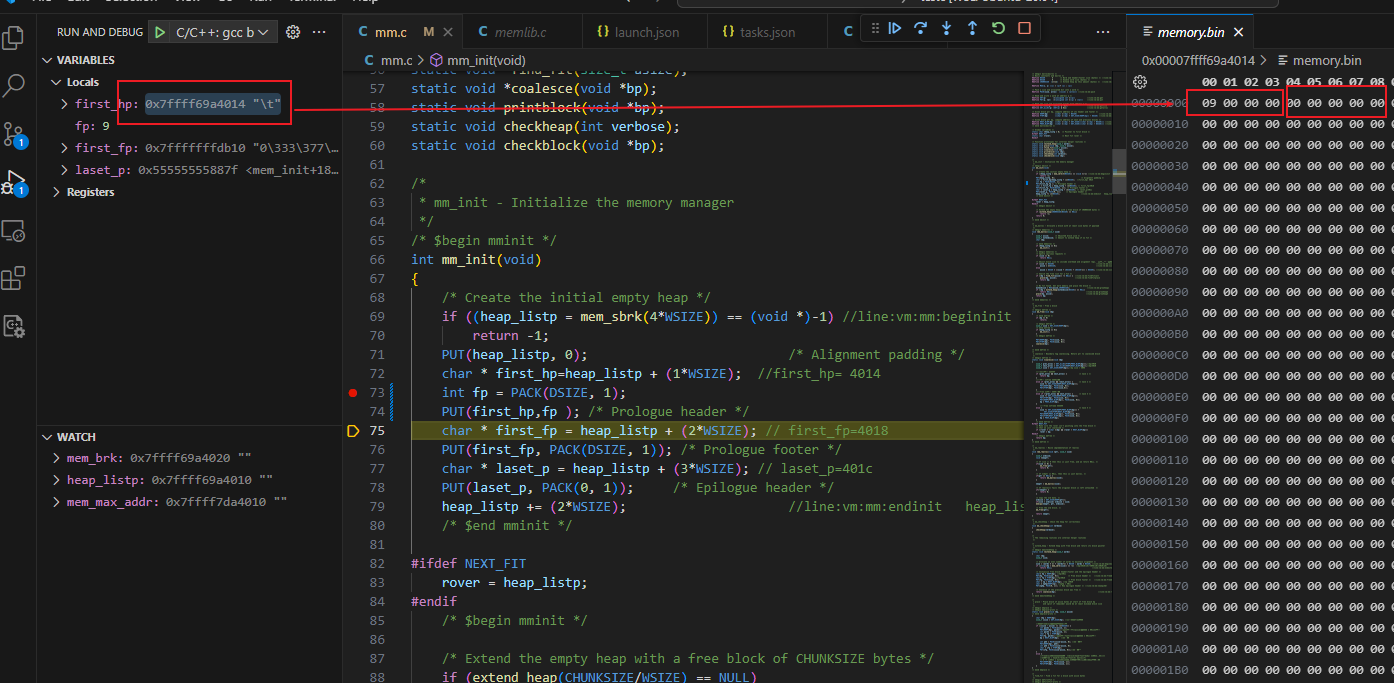
初始化尾节点之后 pack(8,1)=1000|001 =00..001001(二进制) = 00 00 00 09 (32位的十六进制)
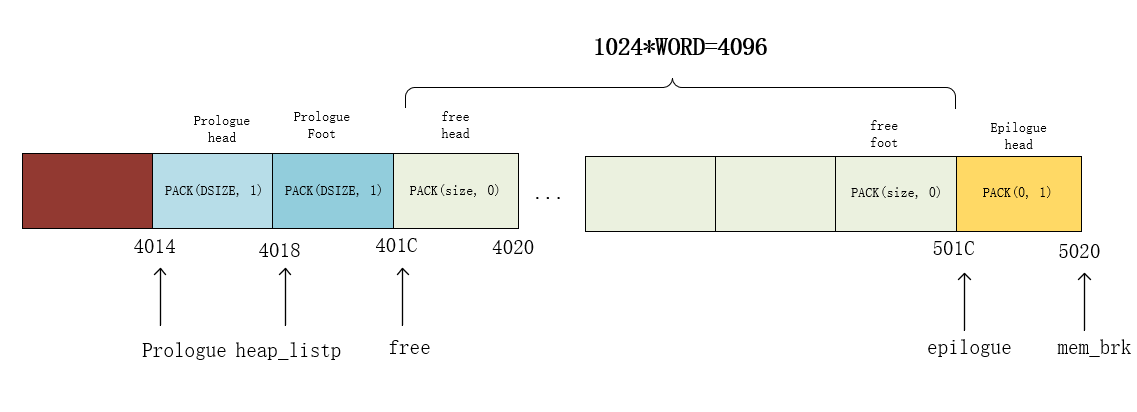
extend_heap(4096) 扩容产生一些free block(4096/4=1024块)
mm_malloc()函数
- 选择一个空闲链表选取算法(下面简单的首次适应算法),找到合适的空闲块
- 分割空闲块为已分配和剩下的
find_fit(size)
找到空闲block,采用首次适应算法
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp)) {
char *hp = HDRP(bp);//获取当前body的头,原理是往4字节,bp-4;
int cur_size = GET_SIZE(hp); //根据头获取body大小
int is_alloc = GET_ALLOC(hp);//根据头获取是否空闲
if ((!is_alloc) && (asize <= cur_size)) {
return bp;
}
}
bp代表当前指针(指向4018),从prologue的body出发,先查看head里面的size和是is_alloc,如图蓝色block,现在size=8,is_alloc=1,均不满足,bp再指向下一个块body(因为知道当前的szie,指针只需要往后走size长度即可)
bp代表当前指针(指向4020),满足条件返回bp=4020
char *oldrover = rover;//上一次找到空闲块的位置
/* rover之后,从 rover 往下找 */
for ( ; GET_SIZE(HDRP(rover)) > 0; rover = NEXT_BLKP(rover))
if (!GET_ALLOC(HDRP(rover)) && (asize <= GET_SIZE(HDRP(rover))))
return rover;
/* rover之前,从头开始找 */
for (rover = heap_listp; rover < oldrover; rover = NEXT_BLKP(rover))
if (!GET_ALLOC(HDRP(rover)) && (asize <= GET_SIZE(HDRP(rover))))
return rover;
return NULL;
place(void *bp, size_t asize)
把空闲块一分为2,构造新的已分配block和空闲block.
static void place(void *bp, size_t asize)
/* $end mmplace-proto */
{
char *hp = HDRP(bp);
size_t csize = GET_SIZE(hp);
if ((csize - asize) >= (2*DSIZE)) {
int pack1 = PACK(asize, 1);
PUT(HDRP(bp), pack1);
int pack2 = PACK(asize, 1);
char * fp = FTRP(bp);
PUT(fp, pack2);
bp = NEXT_BLKP(bp);
int pk3 = PACK(csize-asize, 0);
PUT(HDRP(bp), pk3);
int pk4 = PACK(csize-asize, 0);
PUT(FTRP(bp), PACK(csize-asize, 0));
}
else {
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}
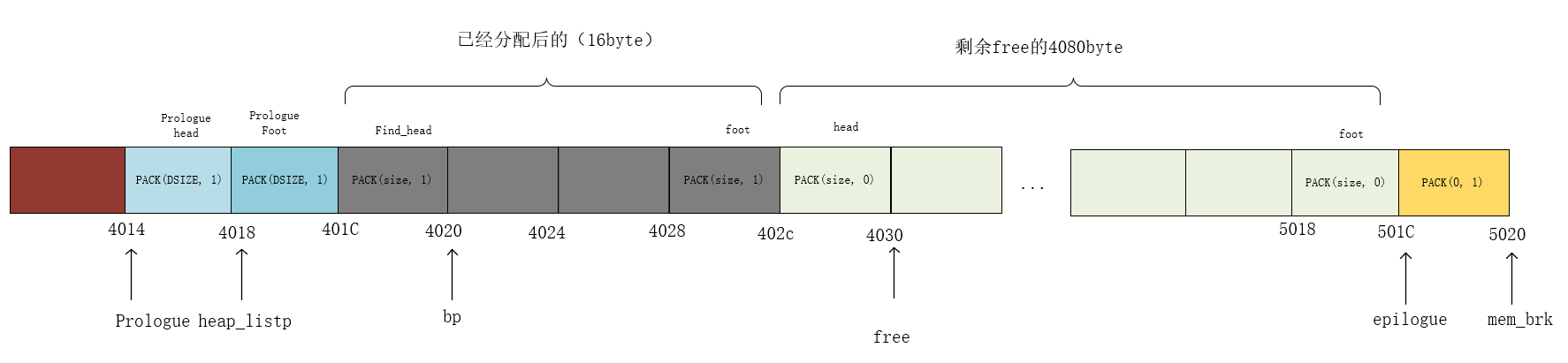
备注: 这里一个int类型,占用了16byte的空间,因为head和foot共8byte,int本身4byte,总共12byte,再对齐(64位系统按8byte对齐)就变成了16byte
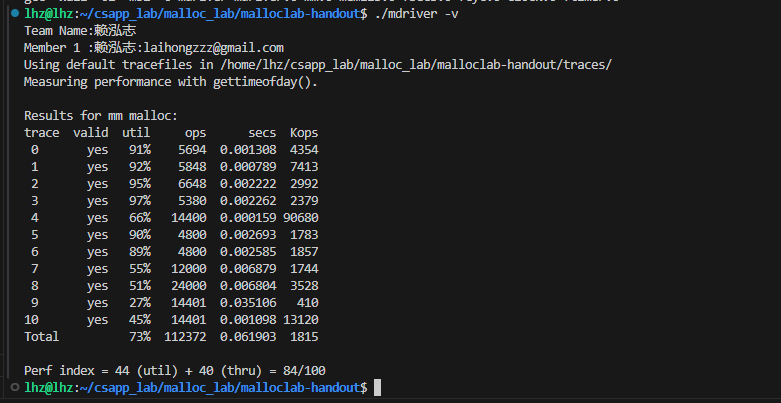
实验结果
我先使用首次适应法,从头开始遍历效率太低
之后采用临近适应算法,效率有明显提高
代码地址