6.s081 xv6-Schedule调度的实现
xv6-源码解析-Schedule
操作系统同有多个进程,但CPU只有一个,为了实现好像进程都在同时执行,时钟中断导致的当前进程让出CPU使用权 完成进程切换的调度过程,这就是调度。
调度原理
用户进程执行一段时间后,操作系统产生时钟中断,中断会从用户态切换到内核态,然后执行trap过程,调用usertrap 函数执行对应的中断处理程序,处理时钟中断会调用yield函数,让出CPU,进入调度(scheduler)线程,调度线程选择一个进程恢复到用户态运行。
void
usertrap(void)
{
int which_dev = 0;
if(r_scause() == 8){
// system call
} else if((which_dev = devintr()) != 0){
// ok
} else {
// exception
}
if(p->killed)
exit(-1);
// give up the CPU if this is a timer interrupt.
// 核心点:如果是时钟中断,则让出当前CPU的使用权
if(which_dev == 2)
yield();
// 从用户陷阱中准备返回
usertrapret();
}
yield
yield很简单,就是修改进程状态,然后调用 sched() ,重要的还是 sched()
进程的状态
UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE。
// Give up the CPU for one scheduling round.
void
yield(void)
{
// 获取当前进程并上锁,加锁是为了保护进程状态结构体的访问互斥性
// 防止在修改进程状态时导致的不变量临时为假的情况
// 这个锁在scheduler中被释放(跨进程)
struct proc *p = myproc();
acquire(&p->lock);
// 首先修改进程状态为RUNNABLE
p->state = RUNNABLE;
// 调用sched完成当前进程上下文的保存
sched();
// 进程再次返回时才可以释放之前持有的锁
// 这个锁之前由scheduler函数获取,在这里释放(跨进程)
release(&p->lock);
}
sched
sched实际调用的是swtch
void
sched(void)
{
int intena;
struct proc *p = myproc();
intena = mycpu()->intena;
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena;
}
swtch (swtch.S)
进程执行需要依赖很多 callee 寄存器,这些 callee 寄存器构成了进程上下文(contxt)
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
swtch 实际就把当前的进程寄存器保存起来,然后恢复上一个进程保存的寄存器
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret
scheduler
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
//选择一个RUNNABLE的进程,分配CPU,开始运行
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
调度流程图
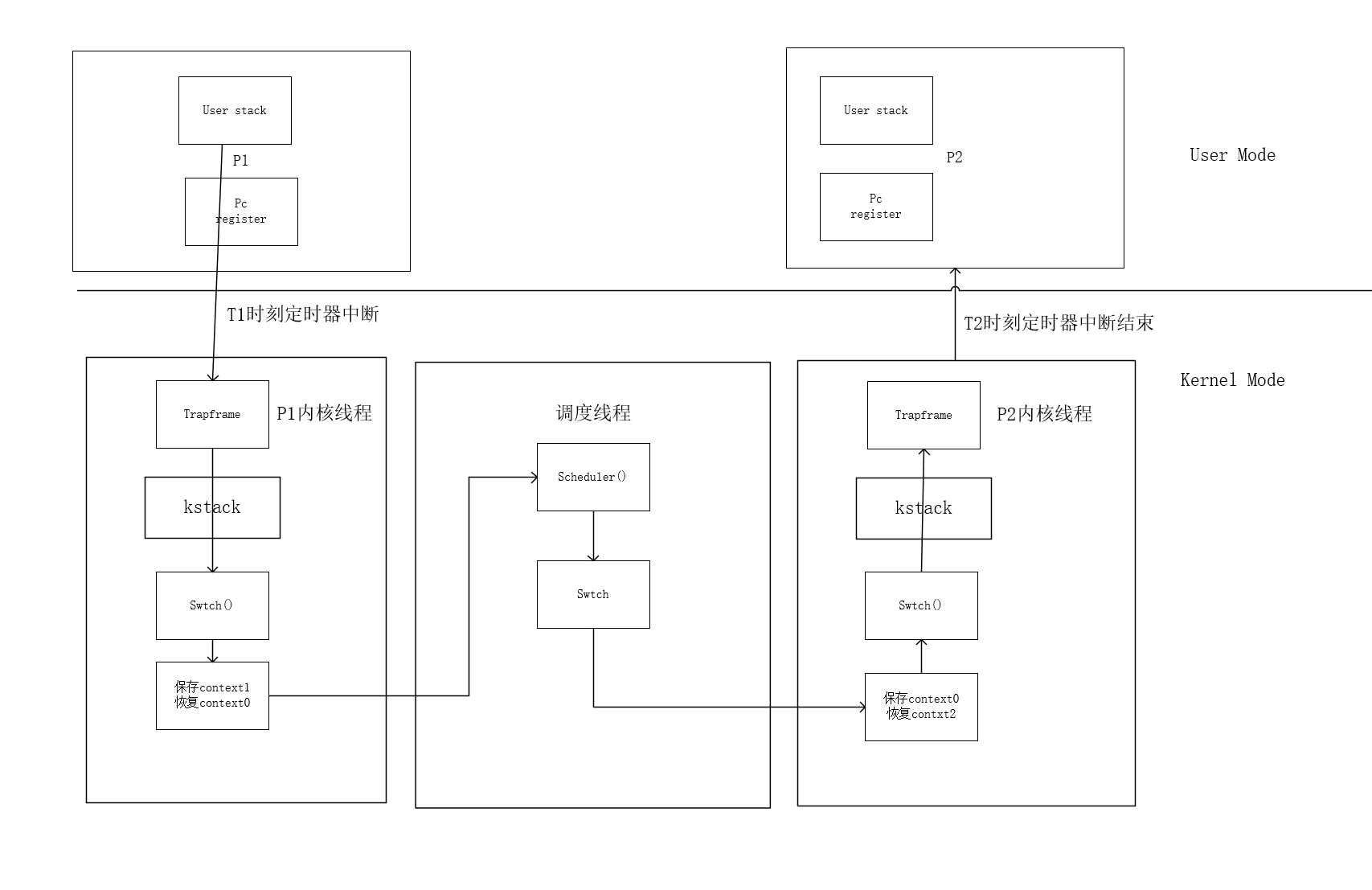
图1 P1切换到P2的流程
用户进程1
P1用户态执行的时候,T1时刻发生始终中断,通过trap过程进入P1的内核态,使用内核栈调用usertrap()函数。
再 usertrap 中调用 yield()->sched()-> swtch()函数,把当前进程的context保存在cpu的context中,恢复调度线程的contxt。(此时P1是停在了sched()的swtch()函数的下一行,也就是mycpu()->intena = intena)
调度线程
此时ra发生改变(之前cpu的contxt所保存的指令地址),会跳转到scheduler()函数里面,也就是c->proc = 0;这一行。
调度线程再循环中找到一个RUNABLE,就绪态的进程,调用swtch(),恢复P2的contxt,再ret到P2上次处理时钟中断的位置
用户进程2
也就是**用户进程1 **进入调度线程的入口下面 **mycpu()->intena = intena **这一行,然后再从yield()返回,回到用户态
void
sched(void)
{
int intena;
struct proc *p = myproc();
intena = mycpu()->intena;
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena;
}
如果此时用户进程2执行一段时间发生时钟中断切换到P1 如下图红色线的流程,与上面一模一样
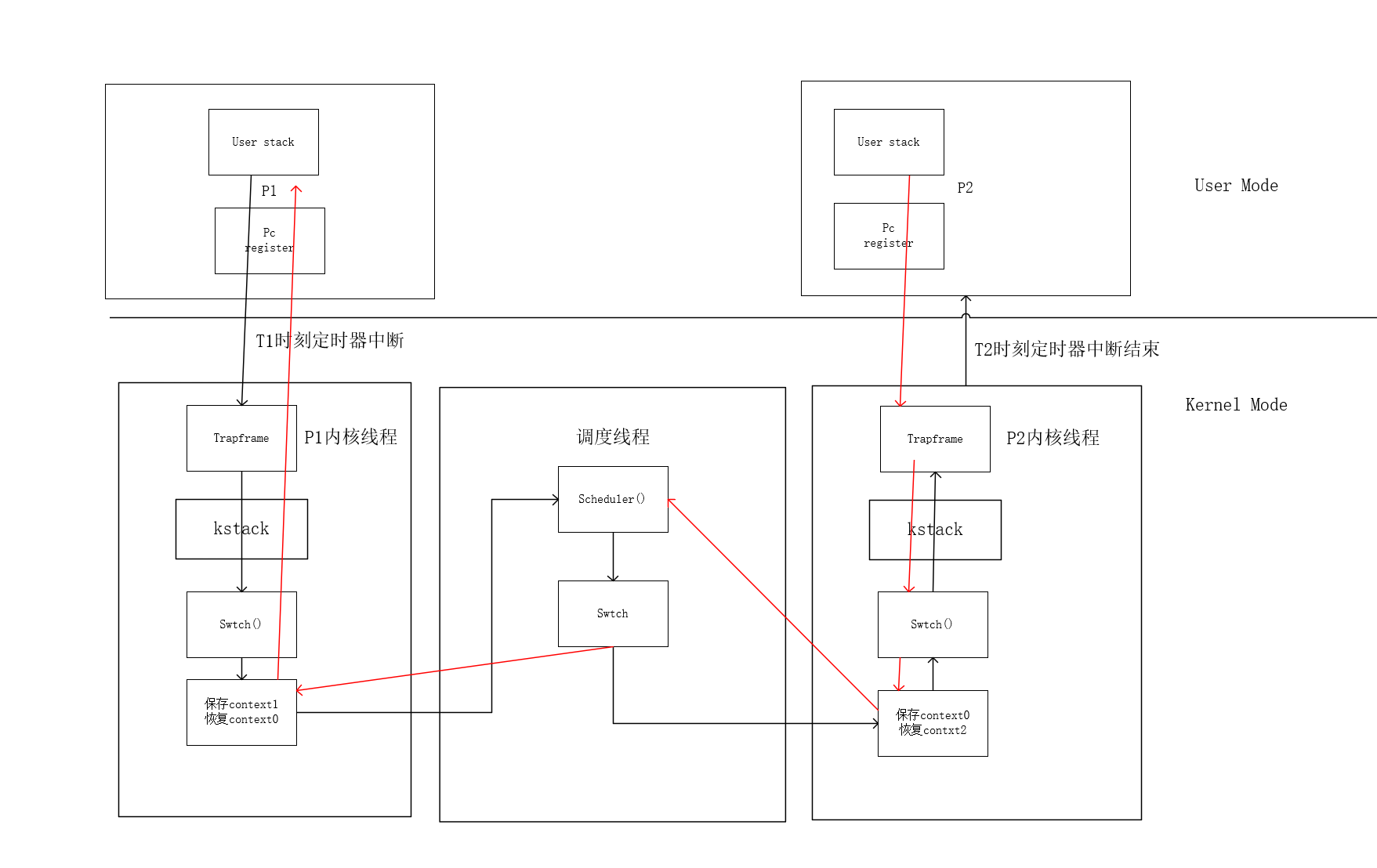
图2 P2切换到P1的流程